
Disclaimer: The opinions expressed by our writers are their own and do not represent the views of U.Today. The financial and market information provided on U.Today is intended for informational purposes only. U.Today is not liable for any financial losses incurred while trading cryptocurrencies. Conduct your own research by contacting financial experts before making any investment decisions. We believe that all content is accurate as of the date of publication, but certain offers mentioned may no longer be available.
As we step into 2026, we reflect on the achievements and shortcomings of the last year and look forward to the exciting new developments coming this year. Many narratives gained hype, but only a few were strong enough to hold the test of time. One of these is the modular nature of the complex scaling solutions.
To rewind, modular protocols envision the blockchain into 4 layers - execution, data availability, settlement and consensus layer. In this article, we’ll revisit the relevance of the execution environment and a data availability layer in building high-data capacity and computationally intensive use cases.
What is an execution environment?
An execution environment is the runtime which processes the transactions. Simply put, it's a blockchain's computing engine, a CPU if you will. In a blockchain setup, execution environments are frequently deterministic such that each node arrives at the same result given the same inputs. All sources of entropy are forbidden, like internal timestamps, randomness, and external calls without constraints.
EVM is the most popular execution environment in the Ethereum ecosystem. It is a stack-based virtual machine. EVM made a breakthrough in blockchain programmability with Turing-completeness. Devs get language that supports jumps, loops, and complex control flow. A couple of high-level languages compile down to EVM bytecode (Solidity, Vyper). Does that work for all use cases? Not really!
Picking an execution environment for your application
EVM remains the go-to choice for most of the developers in the Ethereum space. It offers the simplest path to build, run and deploy contracts. With mature tooling and a vibrant community, it has become the standard machine for many Layer-2 rollups as well.
But EVM is not a silver bullet. We have to think about so many aspects. What kind of apps are you optimizing for? Will your app perform lots of computations or simple state transitions? Is instant composability a must, or is latency outside the dapp domain acceptable? Tooling, financial models, security, there is an infinite list of things to consider.
Things change when devs demand more computational resources and a familiar dev experience as Web 2. Cartesi Machine boots Linux for builders to write deterministic contracts in the language of their choice. This compilation of threads from Felipe explains the Cartesi Machine to beginners really well.

Privacy has evolved as a major theme this year. Enter Programmable cryptography. Think of execution that performs FHE, MPC, zkSNARKs, etc. You may want to pick these protocols for performing execution over sensitive data ranging from your digital identity, private transfers, enterprise solutions, to medical data. Here’s an introductory article you’d love to read https://0xparc.org/blog/programmable-cryptography-1
What is a data availability layer?
Execution environments define how apps compute, whereas the data availability layer defines how inputs to that computation are published and verified. The term is quite often used with rollups transaction batches. DA matters so that anyone can use the input data to execute the transactions and verify the state root of the off-chain rollup machines.
Ethereum has a built-in data availability that is secured by its vast network of validators and stakers. It makes it one of the most secure and reliable ways to read the data. But with great Ethereum security comes great costs. Putting data on Ethereum is costly and scarce. Traditionally, data availability meant storing data forever on-chain. DA solutions and Ethereum itself have evolved into ensuring the input data is publicly retrievable long enough for the network to download and verify it.
Picking the right DA layer for your application
Ethereum made substantial progress with EIP-4844 (proto-danksharding), introducing blobspace that gives rollups dedicated room to post data. The Pectra upgrade further expanded this capacity. Yet, even with these improvements, Ethereum's DA throughput tops out around a few MB per block, which is still a bottleneck for data-hungry applications like on-chain gaming, AI inference, and high-frequency DeFi. Full Danksharding promises 16MB blocks, but that's still years away. For builders who need abundant data capacity today, external DA layers bridge this gap.
When selecting a data availability (DA) layer, several key factors must be considered. Throughput and scalability determine how much data the layer can handle and whether it can grow alongside the application’s demands. The verification speed (DA finality) which defines how quickly nodes can independently verify that the data has been made available. The required level of decentralization depends on the value and sensitivity of the application being secured; for instance, high-value DeFi protocols typically demand stronger decentralization guarantees.
Finally, cost efficiency remains a decisive factor: posting data directly to Ethereum is expensive and scarce, whereas specialized DA layers offer significantly lower costs for comparable data throughput, enabling use cases that were previously impractical, such as social applications, gaming state updates, or frequent oracle submissions.
Avail DA currently supports 4MB blocks with an active roadmap to 10GB. It leverages an expandable blockspace that scales with demand, as more light clients join the network, sampling capacity increases, enabling the network to support larger blocks. This creates a positive feedback loop where security and throughput grow together.
Through the use of validity proofs (KZG commitments) Avail DA allows light clients to verify DA guarantees as soon as blocks are finalized, which is around 20 seconds. This is significantly faster than fraud-proof-based systems that require challenge periods of ~10 minutes or more. For ZK rollups, this is particularly powerful: both execution proofs and DA proofs can be verified rapidly without waiting for dispute windows. The mentioned light clients are lightweight enough to run on mobile devices, smartwatches, and browsers. Through Data Availability Sampling (DAS), these clients achieve near 100% confidence that data is available with just 8-30 random samples.
Avail achieves a high Nakamoto Coefficient through its Nominated Proof-of-Stake (NPoS) consensus, which algorithmically distributes stake evenly across validators using the Phragmén election algorithm, avoiding the concentration risks common in delegated proof-of-stake systems.
What apps are unlocked with DA + Execution combination?
With the DA and Execution layer choices at hand, devs can opt for a combination that fits their needs. Researchers at Cartesi came up with Web 3.0’s Cone of Innovation, which demonstrates the dynamics between Computational and Data-Availability capacity.
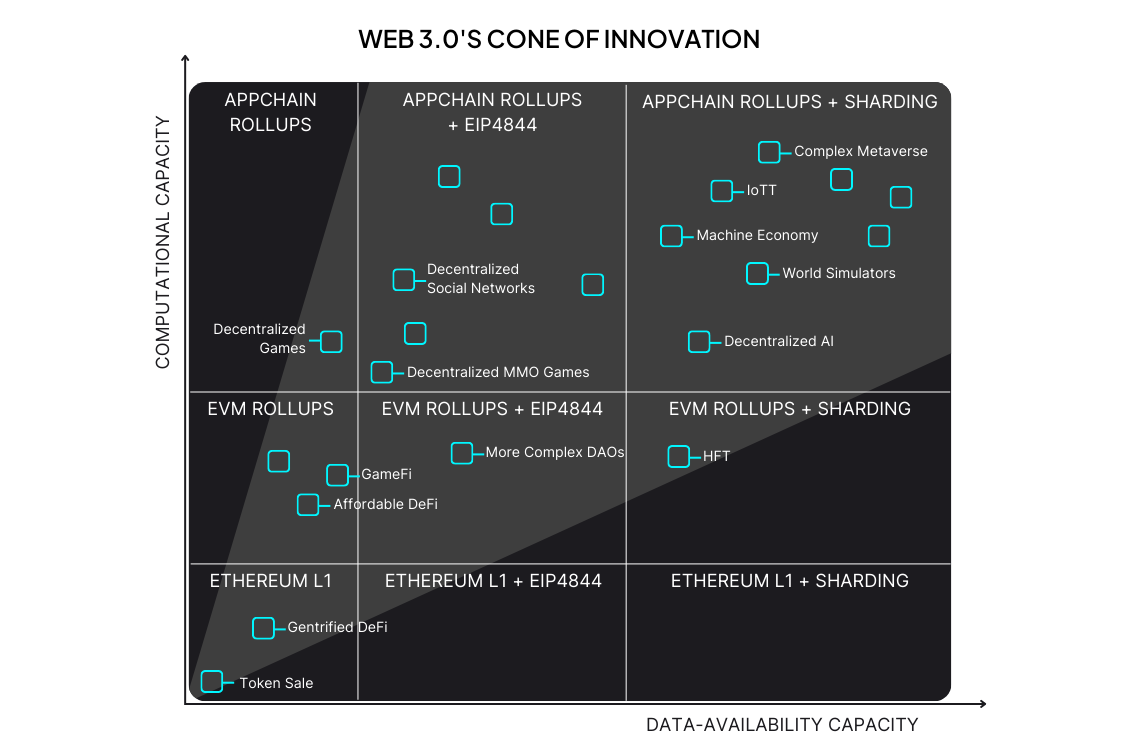
As per the graphical representation, if you were to get a very high DA and Computation, we could see decentralised AI, heavy simulations, and metaverse designs on-chain. These are still ambitious use cases. Let’s look into where we stand today.
We saw Base explode with low-cost SocialFi applications tapping into the Creators economy. Projects in this domain include Farcaster, Zora, which require high DA and low transaction costs.
Uniswap made a significant move to release its own appchain, again, to lower costs and deliver high throughput. You would also find perpetual DEXs shifting in the dedicated Appchain direction.
Running games on-chain requires medium to high computation and data. You would see more specialised Appchains in this domain. Immutable, Dojo, among others, provide a suite of tools for game developers.
Other classic use-cases of stablecoins, RWAs, and NFTs require low compute and minimal DA. These apps largely stayed bottom-left region of the graph.
Examples listed above give us a fair picture of how the Cone of Innovation is coming to life. Apps are moving towards gaining more control over the available computational resources and data.
Conclusion: Where are we headed in 2026?
Scaling solutions for Ethereum have given more choices for developers, but at the same time, introduced a fragmentation problem. Bridging and hopping chains is not our end goal. To solve this, we witnessed aggregation and interoperability solutions gaining heat. Next year, we could see these solutions become more mainstream and established standards. From the user’s perspective, the endgame is abstraction. Infrastructure maturity should converge to make decentralised apps meet the UX quality of Web 2.
With the advent of novel execution environments, we’ll see more use cases being experimented with. More hybrid apps with public and private execution. Proving the computations on-chain goes hand-in-hand. Permissionless protocols that allow low CPU resources and minimal costs will give a higher degree of decentralisation.
Authors:
Joao Garcia, head of DevRel at Cartesi and Avail team
 Dan Burgin
Dan Burgin U.Today Editorial Team
U.Today Editorial Team